
Hi,
I love TextMate2 because of its multi-lingual capability. It is awesome (it is better than Sublime, IMHO), but there is a chronic problem regarding soft-wrap.
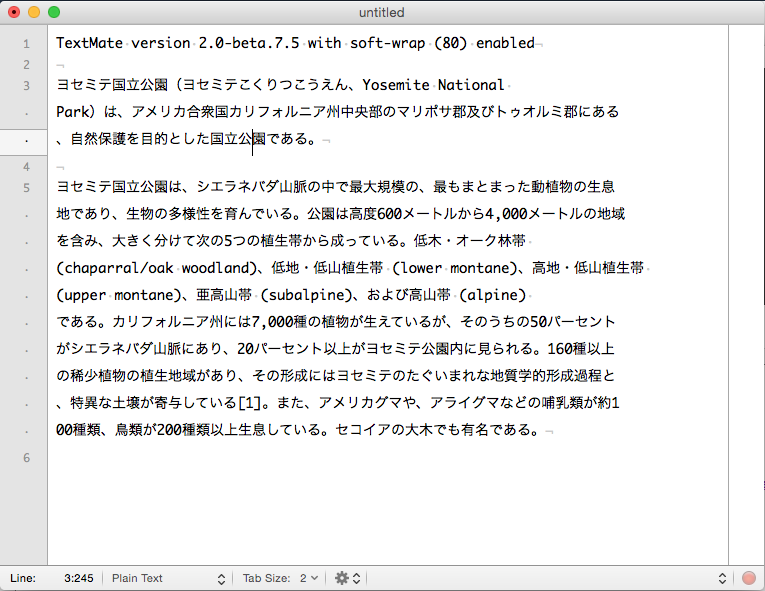
When I have multi-byte (CJK) characters and regular single-byte ones in the same line, soft-wrap does not work very nicely. Please see the attached png.
When the line consists only of characters of the same type, multi-byte or single-byte, soft-wrap works just fine. When they are mixed, however, the right-hand side of wrapped text looks quite bad.
Is there a quick way to avoid this? Or is this something that needs an application level fix?
I suspect TM2 treats a sequence of multi-byte characters as if it was a single word. If that is the case, with text in a language like Japanese, where word boundaries are not indicated by spaces, a whole sentence or even a paragraph will be processed as just one huge word.
Regards, Yoichiro
{kind=link}

On 27 Jun 2015, at 6:33, Yoichiro Hasebe wrote:
I suspect TM2 treats a sequence of multi-byte characters as if it was a single word. If that is the case, with text in a language like Japanese, where word boundaries are not indicated by spaces, a whole sentence or even a paragraph will be processed as just one huge word.
Correct, TextMate will need to learn about word boundaries for languages that do not use space characters, to do proper wrapping.
I see CFString has hyphenation API since 10.7, so this might be usable, but I will need to investigate this a bit further, also, wrapping is not the only place where word boundaries come up, so the “fix” would need to go beyond just wrapping (e.g. word movement and selection should also use linguistic word boundary definitions).
-
 Allan Odgaard
Allan Odgaard -
 Yoichiro Hasebe
Yoichiro Hasebe