
For the placeholder of special characters (<U+XXXX>s), the bidirectional category of placeholders should match the bidirectional category of the original character. Although I guess almost all of those special characters which are represented by <U+XXXX> belongs to Boundary_Neutral class.
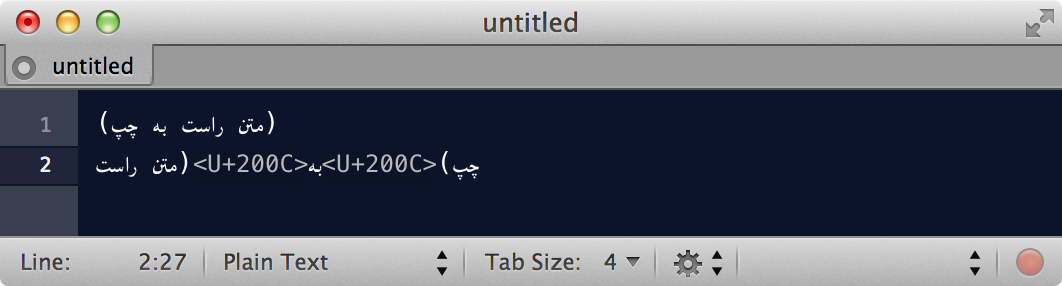
For example, here you can see what has happened when I've replaced 2 spaces with Zero-width non-joiners:
[image: تصویر درون برنامهای 1]
Here is the textual version, which is rendered correctly in my browser (Chrome 33):
(متن راست به چپ) (متن راستبهچپ)
Properties of U+200C: http://unicode.org/cldr/utility/character.jsp?a=200C
I'm interested in working on it and submitting a pull request, if you accept this semi-feature-request and specify which solution is preferred. I have a workaround suggestion: replacing them with some symbolic characters, for example ⦿ for null, ↩︎ for line separator, ╵ for zero-width space, ╽ for zero-width non-joiner, ╈ zero-width joiner, ...
Best regards Reza
{kind=link}

On 8 Mar 2014, at 20:41, Reza Mohammadi wrote:
[…] I'm interested in working on it and submitting a pull request, if you accept this semi-feature-request and specify which solution is preferred. I have a workaround suggestion: replacing them with some symbolic characters, for example ⦿ for null, ↩︎ for line separator, ╵ for zero-width space, ╽ for zero-width non-joiner, ╈ zero-width joiner, ...
I am not familiar with the intricacies of bidirectional rendering, so I cannot say what solution is preferred, though substituting the unicode code point renderings with somewhat arbitrary placeholders is not something I consider an improvement.
Perhaps some of the invisible spaces should just be rendered as-is (without a substitution), I translated them to visible code points only because invisible characters have a tendency to cause hard to diagnose problems for end users, but this might be limited to non-breaking space, which can easily be typed by accident without noticing.
-
 Allan Odgaard
Allan Odgaard -
 Reza Mohammadi
Reza Mohammadi