
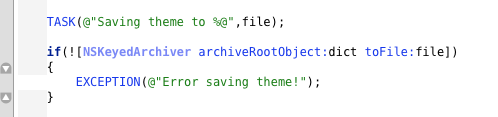
I take exception to the C syntax gobbling up whitespace at the beginning of a line. It screws up my tab guides, as seen in the example below (before EXCEPTION).
Gerd
{kind=link}

So I guess I should explain why I added the leading spaces scope to the grammar.
TextMate syntax parser works as follows,
for each line there will be a bunch of rules (the regexes in the language files), that needs to be tested, these rules vary depending on scope and other stuff.
the way that textmate knows which rule "wins" depends on the following,
first the start position if there is a tie the order in which the rules are defined, determines the winner.
So how does this affect the C grammar? the way that I differentiate between function definitions and function calls in the C grammar, is that I start a new Scope when I encounter {...}, inside the braces rule I place an identical rule to the function definition matcher. Since these rules are identical there will be a tie when looking at just the start postion of the match, so order will determine. Outside of {...} the function-call rule will not win since it isn't even defined there.
So what is the problem? In short C++, there are a few constructs in C++ that looks like this
void foo(){ std::string myString("hello world"); }
Since we want to differentiate between function-calls and variable initialization such as the one above, we need a rule that matches those, for technical reasons that rule needs to match the leading spaces. Trouble is, this will make the rule win over the function-call rule, as the leading spaces will ensure a "headstart". It does not matter that it has lower precedence than the function-call rule.
Hopefully this explains things, If anyone can think of a better solution please mail ideas.
To Hans and everyone interested: Hans, I assume that you have defined a "super" grammar that includes the C and Objective-C ones, in that case the problem is that your additional rules gets included at the root level, and that is included after the function-call matching inside {...}, this will probably be solvable once Allan adds injections. Anyway perhaps you could send your grammar file and we can decide on a format so that leading spaces will get scoped uniformly.
Joachim Mårtensson
I get that. However could the same not be achieved without actually consuming the whitespace, eg with lookahead/lookbehind?
Gerd
On Feb 8, 2008, at 12:23 PM, Joachim Mårtensson wrote:
So I guess I should explain why I added the leading spaces scope to the grammar.
TextMate syntax parser works as follows,
for each line there will be a bunch of rules (the regexes in the language files), that needs to be tested, these rules vary depending on scope and other stuff.
the way that textmate knows which rule "wins" depends on the following,
first the start position if there is a tie the order in which the rules are defined, determines the winner.
So how does this affect the C grammar? the way that I differentiate between function definitions and function calls in the C grammar, is that I start a new Scope when I encounter {...}, inside the braces rule I place an identical rule to the function definition matcher. Since these rules are identical there will be a tie when looking at just the start postion of the match, so order will determine. Outside of {...} the function-call rule will not win since it isn't even defined there.
So what is the problem? In short C++, there are a few constructs in C++ that looks like this
void foo(){ std::string myString("hello world"); }
Since we want to differentiate between function-calls and variable initialization such as the one above, we need a rule that matches those, for technical reasons that rule needs to match the leading spaces. Trouble is, this will make the rule win over the function-call rule, as the leading spaces will ensure a "headstart". It does not matter that it has lower precedence than the function-call rule.
Hopefully this explains things, If anyone can think of a better solution please mail ideas.
To Hans and everyone interested: Hans, I assume that you have defined a "super" grammar that includes the C and Objective-C ones, in that case the problem is that your additional rules gets included at the root level, and that is included after the function-call matching inside {...}, this will probably be solvable once Allan adds injections. Anyway perhaps you could send your grammar file and we can decide on a format so that leading spaces will get scoped uniformly.
Joachim Mårtensson
For new threads USE THIS: textmate@lists.macromates.com (threading gets destroyed and the universe will collapse if you don't) http://lists.macromates.com/mailman/listinfo/textmate
I get that. However could the same not be achieved without actually consuming the whitespace, eg with lookahead/lookbehind?
Gerd
Unfortunately lookbehinds can not be variable length. And since we want to allow arbitrary amount of spaces between "tokens" this is the solution we need to adopt. I can not see a good reason for why say [a-z]* should not be able to be used in a lookbehind but that is the case.
Sorry for calling you Hans by the way, for some reason I assumed you were Hans-Jörg Bibiko.
Joachim Mårtensson

On Feb 7, 2008, at 1:01 PM, Gerd Knops wrote:
I take exception to the C syntax gobbling up whitespace at the beginning of a line. It screws up my tab guides, as seen in the example below (before EXCEPTION).
I'll just echo here what Joachim has said… Sometimes matching entire lines is necessary grammar wise. It'd be great if it wasn't but I think that's not really feasible for all cases.
I've also talked with SubtleGradient a lot about this as he wants the same in the main Javascript and CSS grammars. I think it's a bad precident to set because once you start adding it to one official grammar it becomes a standard feature that people will end up wanting elsewhere. Scope wise I think it's tends to be bad because it can easily double or even triple the number of scopes in a document. Of course that probably sounds hollow as I've been responsible for adding tons of scopes… but it still seems bad to add so many just for a single feature.
I don't know where allan's stance is, but my view is that this should be a TextMate level feature, built into the editor and completely separated from the grammars. It would then work everywhere, even when an entire line is matched. If it was tied into the folding perhaps even allow better coloring as you could the entire clock for a color, something like XCode.

On Feb 8, 2008, at 4:21 PM, Michael Sheets wrote:
I don't know where allan's stance is, but my view is that this should be a TextMate level feature, built into the editor and completely separated from the grammars. It would then work everywhere, even when an entire line is matched. If it was tied into the folding perhaps even allow better coloring as you could the entire clock for a color, something like XCode.
I totally agree that this sort of thing should be a TextMate level feature. I hate repeating the same code in multiple grammars.
But, if a feature is possible to implement with the current system, and the pros outweigh the cons, then I'd say let's do it.
On this feature in particular, it's extremely handy to have the leading space scopes available in HTML, Javascript, Ruby and almost every other language on earth. Mostly just for theme support.
But what are the downsides? Adding too many irrelevant scopes to the document. When converting the scopes to HTML you get a giant glob of carp at the beginning of every line. That could be averted with a simple blacklist of scopes that should be ignored from the conversion process.
Other than that, what's other downsides are there?
—Thomas Aylott – subtleGradient—
On Feb 10, 2008, at 9:22 AM, Thomas Aylott - subtleGradient wrote:
But what are the downsides? Adding too many irrelevant scopes to the document. When converting the scopes to HTML you get a giant glob of carp at the beginning of every line. That could be averted with a simple blacklist of scopes that should be ignored from the conversion process.
Other than that, what's other downsides are there?
Well for Javascript this isn't a downside, since it doesn't have any line-based scopes. But most grammars match entire lines at some point, adding tab scopes to each of those would get very messy quite fast. Depending how many tabs you allow that's 5+ captures, double it if you have a different scope for spaces over tabs like your current version does for each rule.
Speed-wise I'm not sure what kind of hit it takes from assigning the tab scopes, allan could perhaps answer this.
--
Another thing to ask here is how it could be implemented as a TextMate level feature.
I see two approaches, one is basically what you do. Have some dynamic scopes added for each leading tab/soft-tab, can color these in themes. Logistically pretty simple I'd imagine, not much to figure out.
The second is what people have pointed out here before as cool, the more XCode like coloring:
http://skitch.com/infininight/gdfw/nstextview-edit-in-textmate.mm
Where it colors blocks not really the tabs themselves. A bit niftier perhaps? But logistically harder perhaps. Are they no longer based on tabs at all, or are they simply anything foldable gets a new 'level'? If they are still tab based what do you do about something like a two- line item when the second line is indented, you wouldn't want it made a new 'level'. The limitation here is the places where the folding system isn't ideal, but then that's something that will hopefully improve so tieing them together might make it easy.
Any other ways this could be done?
On Feb 11, 2008, at 3:43 AM, Michael Sheets wrote:
On Feb 10, 2008, at 9:22 AM, Thomas Aylott - subtleGradient wrote:
But what are the downsides? Adding too many irrelevant scopes to the document. When converting the scopes to HTML you get a giant glob of carp at the beginning of every line. That could be averted with a simple blacklist of scopes that should be ignored from the conversion process.
Other than that, what's other downsides are there?
Well for Javascript this isn't a downside, since it doesn't have any line-based scopes. But most grammars match entire lines at some point, adding tab scopes to each of those would get very messy quite fast. Depending how many tabs you allow that's 5+ captures, double it if you have a different scope for spaces over tabs like your current version does for each rule.
There are a few places where I've had to capture the leading space, but you just have to include the #leading-space thing and you're good to go. Obviously wouldn't work if that space was taken in a different way though.
Speed-wise I'm not sure what kind of hit it takes from assigning the tab scopes, allan could perhaps answer this.
That is definitely something to consider. Unfortunately it's currently impossible to run tests on a language grammar. I'd like to see that as a feature sometime in the future. Maybe hook into the mate function to test any tmlanguage file against any text file and get some statistics or something useful. Maybe a breakdown of what scopes are taking how long so that you can focus your energies on fixing that stuff.
I know there are a million different ways of doing a regex, and some ways are much more betterer than others. So anything that can help me see which of my regex look to be written by rabid lemurs would be useful.
--
Another thing to ask here is how it could be implemented as a TextMate level feature.
I see two approaches,
Actually, I think it actually makes good sense to make it 2 separate features. Style the leading space dynamically AND Xcode-esque dynamic nested group coloring.
one is basically what you do. Have some dynamic scopes added for each leading tab/soft-tab, can color these in themes. Logistically pretty simple I'd imagine, not much to figure out.
I think it could be like we currently have "Highlight current line" as a preference checkbox and a hardcoded theme color. If we just standardize on odd-tab coloring checkbox+theme color. Then it's very simple. That way the textmate level implementation of it is really none of our business, Allan can make it happen however he likes without polluting the scope structure with otherwise worthless scopes.
The second is what people have pointed out here before as cool, the more XCode like coloring:
http://skitch.com/infininight/gdfw/nstextview-edit-in-textmate.mm
Where it colors blocks not really the tabs themselves. A bit niftier perhaps? But logistically harder perhaps. Are they no longer based on tabs at all, or are they simply anything foldable gets a new 'level'? If they are still tab based what do you do about something like a two-line item when the second line is indented, you wouldn't want it made a new 'level'. The limitation here is the places where the folding system isn't ideal, but then that's something that will hopefully improve so tieing them together might make it easy.
This is really a completely different feature.
I love how Xcode has it built into the folding system. It also solves the issue for themes where too many nested groups can become unmanageable. In my current implementation I have to manually add each group with its background color hard coded. Themes could instead have 3–4 background colors that are manually set, or else textmate will fallback to some sort of default. And then have a checkbox in the prefs like "Highlight current line"
I'd also like the option of activating the coloring based on caret position instead of having to mouse over the gutter like in Xcode.
So, yes. Based on folding is probably the best option for this feature.
I also REALLY like the way xcode folds code into a single character instead of folding into a single line like textmate currently does.
Any other ways this could be done?
On Feb 11, 2008, at 7:43 AM, Thomas Aylott - subtleGradient wrote:
Well for Javascript this isn't a downside, since it doesn't have any line-based scopes. But most grammars match entire lines at some point, adding tab scopes to each of those would get very messy quite fast. Depending how many tabs you allow that's 5+ captures, double it if you have a different scope for spaces over tabs like your current version does for each rule.
There are a few places where I've had to capture the leading space, but you just have to include the #leading-space thing and you're good to go. Obviously wouldn't work if that space was taken in a different way though.
Most of the line-based scopes capture "^\s*foo" as the begin, I guess you could a look-ahead to get into the patterns immediately but then your into making it more complicated which was my point. ;)
I'd also like the option of activating the coloring based on caret position instead of having to mouse over the gutter like in Xcode.
You can do this in XCode, View → Folding → Focus follows selection. Took me forever to figure out how to take that screenshot. ;)
On Feb 12, 2008, at 1:58 AM, Michael Sheets wrote:
On Feb 11, 2008, at 7:43 AM, Thomas Aylott - subtleGradient wrote:
Well for Javascript this isn't a downside, since it doesn't have any line-based scopes. But most grammars match entire lines at some point, adding tab scopes to each of those would get very messy quite fast. Depending how many tabs you allow that's 5+ captures, double it if you have a different scope for spaces over tabs like your current version does for each rule.
There are a few places where I've had to capture the leading space, but you just have to include the #leading-space thing and you're good to go. Obviously wouldn't work if that space was taken in a different way though.
Most of the line-based scopes capture "^\s*foo" as the begin, I guess you could a look-ahead to get into the patterns immediately but then your into making it more complicated which was my point. ;)
Well then, um… yeah
I'd also like the option of activating the coloring based on caret position instead of having to mouse over the gutter like in Xcode.
You can do this in XCode, View → Folding → Focus follows selection. Took me forever to figure out how to take that screenshot. ;)
I look forward to using that soon.
—Thomas Aylott – subtleGradient—
-
 Gerd Knops
Gerd Knops -
 Joachim Mårtensson
Joachim Mårtensson -
 Michael Sheets
Michael Sheets -
 Thomas Aylott - subtleGradient
Thomas Aylott - subtleGradient