
Hi, [sorry, a bit complicated]
my bundle "R Console (Rdaemon)" ships with a grammar called "LaTeX Rdaemon" which works under TM 1.5 without problems but under TM 2.0 it fails partially.
It a bit complicated that's why a bit background information: This grammar allows the users to write a normal LaTeX document with an interactive R Console running inside of the LaTeX document. [a kind of interactive Sweaving]
Here a minimal tex example: ------- % Preamble (fold)
\documentclass[11pt]{article} \usepackage{blindtext} \usepackage{verbatim} \newenvironment{Rdaemon}{\comment}{\endcomment} % R code invisible
\begin{document}
\section{First section}
\blindtext
\begin{Rdaemon}
runif(10,min=0,max=1)
\end{Rdaemon}
\section{Second Section} \blindtext
\end{document} -------
Everything between \begin{Rdaemon} and \end{Rdaemon} should controlled by the "R Console (Rdaemon)" bundle scope: 'source.rd.console' and its output will be syntax highlighted via 'source.r' which works under TM 2.0.
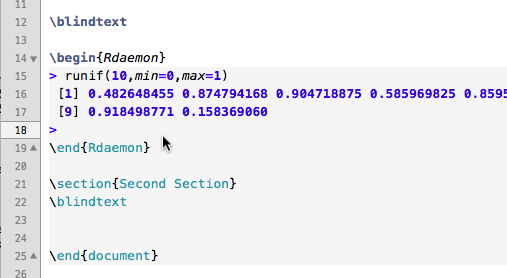
If I place the caret after "runif(10,min=0,max=1)" and press ENTER "runif(10,min=0,max=1)" will be sent to R und the result will be inserted like:
------- ... \blindtext
\begin{Rdaemon}
runif(10,min=0,max=1)
[1] 0.482648455 0.874794168 0.904718875 0.585969825 0.859514066 0.865195652 0.003995807 0.904800528 [9] 0.918498771 0.158369060
\end{Rdaemon}
\section{Second Section} ... -------
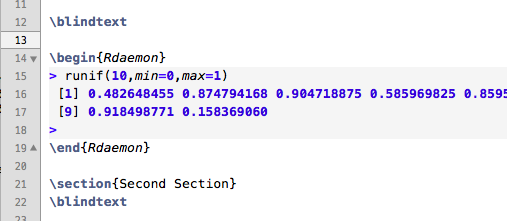
Fine, but for some reasons in TM 2.0 the end tag "\end{Rdaemon}" isn't recognized. I looked into that and it seems to me that the grammar definition of 'source.rd.console.prompt' in "R Console (Rdaemon)" "eats" the entire rest of the tex document:
{ name = 'source.rd.console.prompt'; begin = '^[>+:] '; end = '\n\z'; beginCaptures = { 0 = { name = 'keyword.other.embedded.rd.console'; }; }; patterns = ( { include = 'source.r'; } ); },
[well at least it's my finding ;)]
Correct:
but in TM 2.0 it looks like:
Is anyone out there who can help me fixing it?
Thanks a lot, Hans
{kind=link}
{kind=link}
On Apr 9, 2014, at 7:25 PM, Hans-Jörg Bibiko wrote:
{ name = 'source.rd.console.prompt'; begin = '^[>+:] '; end = '\n\z'; beginCaptures = { 0 = { name = 'keyword.other.embedded.rd.console'; }; }; patterns = ( { include = 'source.r'; } ); },
I believe I found the issue here - or better said - two issues.
As I said, I tried several possible solutions to fix the problem, and by doing this I assumed that ANY change in the grammar will force TM 2.0 to reload the doc on basis of the new grammar - but I learnt not ANY change will be recognized on-the-fly.
What I now did: I removed the "\z" in the "end" clause AND restarted TM 2.0 - after that the LaTeX RDaemon grammar works fine so far.
The question now is - apart from the updating behaviour after changing a grammar (maybe beta-status) - what is difference between TM 1 and 2 in that respect? For Oniguruma a \z is the absolute end of a string regardless of \n. Was there a change from TM 1 to 2?
Kind regards, Hans

On Apr 9, 2014, at 4:18 PM, Hans-Jörg Bibiko bibiko@eva.mpg.de wrote:
The question now is - apart from the updating behaviour after changing a grammar (maybe beta-status) - what is difference between TM 1 and 2 in that respect? For Oniguruma a \z is the absolute end of a string regardless of \n. Was there a change from TM 1 to 2?
For 1.x there was no specified behavior for \z and it wasn’t really a benefit to using it, so it just behaved in the default manner in Oniguruma. For 2.0 it means the literal end of the document.
On Apr 10, 2014, at 1:26 AM, Michael Sheets wrote:
For 1.x there was no specified behavior for \z and it wasn’t really a benefit to using it, so it just behaved in the default manner in Oniguruma. For 2.0 it means the literal end of the document.
Thanks Michael,
hmm, or the other way around - it could be the case that TM1's syntax highlighting engine was really line based i.e. each single line was checked against the grammar one after the other uncoupled from the entire doc whereby TM2's engine "is a bit more document based".
Cheers, Hans
On Apr 9, 2014, at 6:46 PM, Hans-Jörg Bibiko bibiko@eva.mpg.de wrote:
hmm, or the other way around - it could be the case that TM1's syntax highlighting engine was really line based i.e. each single line was checked against the grammar one after the other uncoupled from the entire doc whereby TM2's engine "is a bit more document based".
The grammars are still totally line-based, the handling of \z is special cased when parsing the grammar to only match on the last line.

On 10 Apr 2014, at 6:46, Hans-Jörg Bibiko wrote:
hmm, or the other way around - it could be the case that TM1's syntax highlighting engine was really line based i.e. each single line was checked against the grammar one after the other uncoupled from the entire doc whereby TM2's engine "is a bit more document based".
Yes, for TM 2 \A and \z are “document anchors” instead of line anchors (and \G has also been given meaning beyond Ongiruma’s default behavor).
As for TM not noticing grammar changes, this would normally be when editing an included or injected grammar, in this case a relaunch is required. Editing root grammars should have the changes take effect when saving the grammar, and yes, it’s something I consider a temporary limitation.
On Apr 10, 2014, at 4:05 AM, Allan Odgaard wrote:
Yes, for TM 2 \A and \z are “document anchors” instead of line anchors (and \G has also been given meaning beyond Ongiruma’s default behavor).
As for TM not noticing grammar changes, this would normally be when editing an included or injected grammar, in this case a relaunch is required. Editing root grammars should have the changes take effect when saving the grammar, and yes, it’s something I consider a temporary limitation.
Thanks a lot for the clarification!
Best, Hans
-
 Allan Odgaard
Allan Odgaard -
 Hans-Jörg Bibiko
Hans-Jörg Bibiko -
 Michael Sheets
Michael Sheets